now
NeMo Retriever Extraction
2025
Depression's Proteomic Architecture
Sustainably Advancing Health AI
Waypoint
CPU-GPU Hybrid LLM Inference
BlueTape
2024
Molecular Dynamics at J&J
Heart Murmur Detection
DNN Primitives
TinyConv
JournalAI
MiniTorch
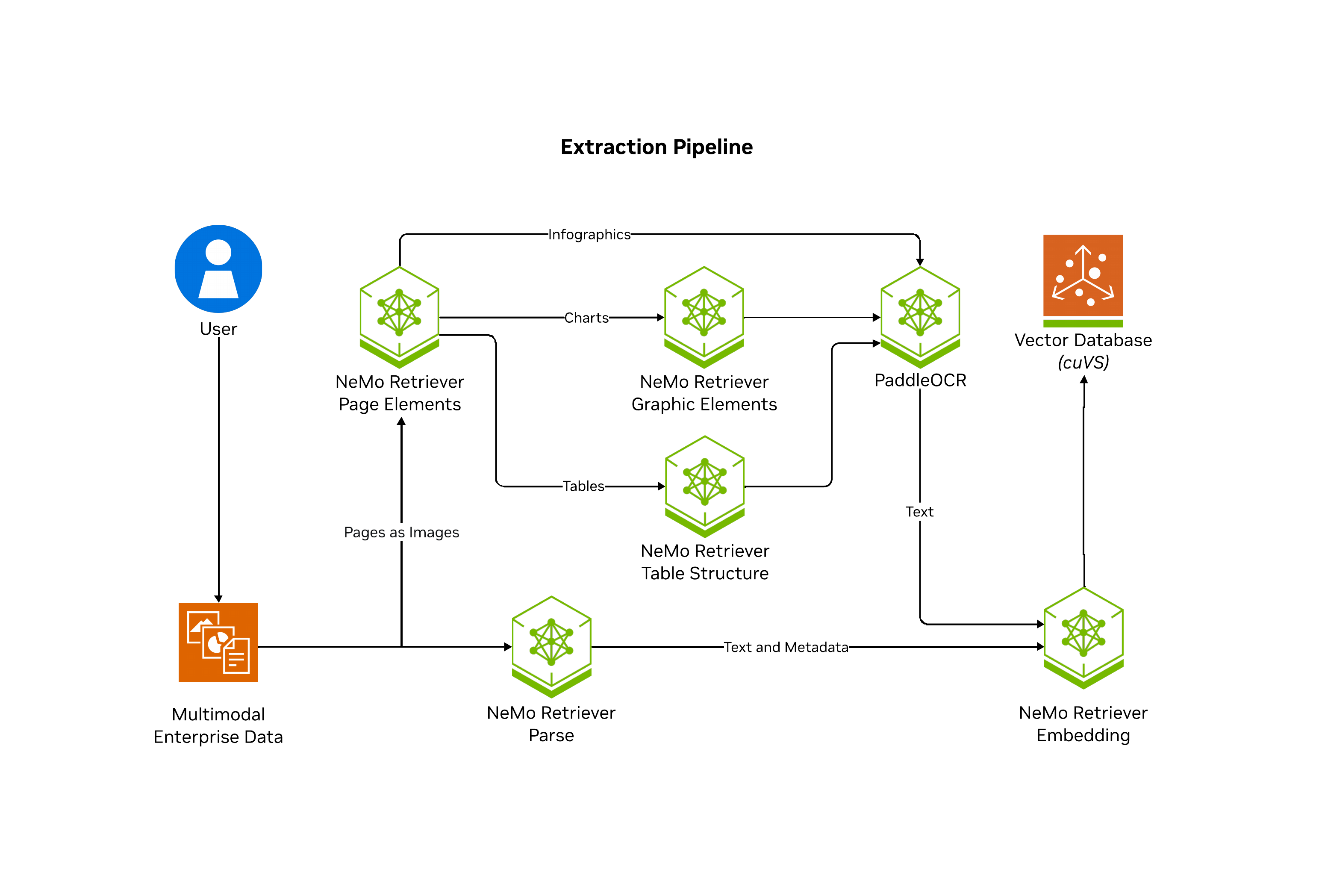
A scalable, performance-oriented document content and metadata extraction microservice. Uses specialized NVIDIA NIM microservices to find, contextualize, and extract text, tables, charts, and infographics for downstream generative applications.
A deep learning system for analyzing depression's proteomic architecture using UK Biobank data (53,000+ participants, 2,900 proteins). Implements Improved Deep Embedded Clustering with a symmetric autoencoder to investigate biological subtypes.
Research with Weill Cornell Medicine under Dr. Logan Grosenick, Dr. Connor Liston, and Elias Scheer.

Exploring how implementation of LLMs impacts energy, sustainability, and cost in the Stanford Medical System.

An AI-powered research compliance automation system that streamlines the intake and routing of institutional review requests. Features document classification, requirement extraction, and intelligent routing to relevant compliance offices.

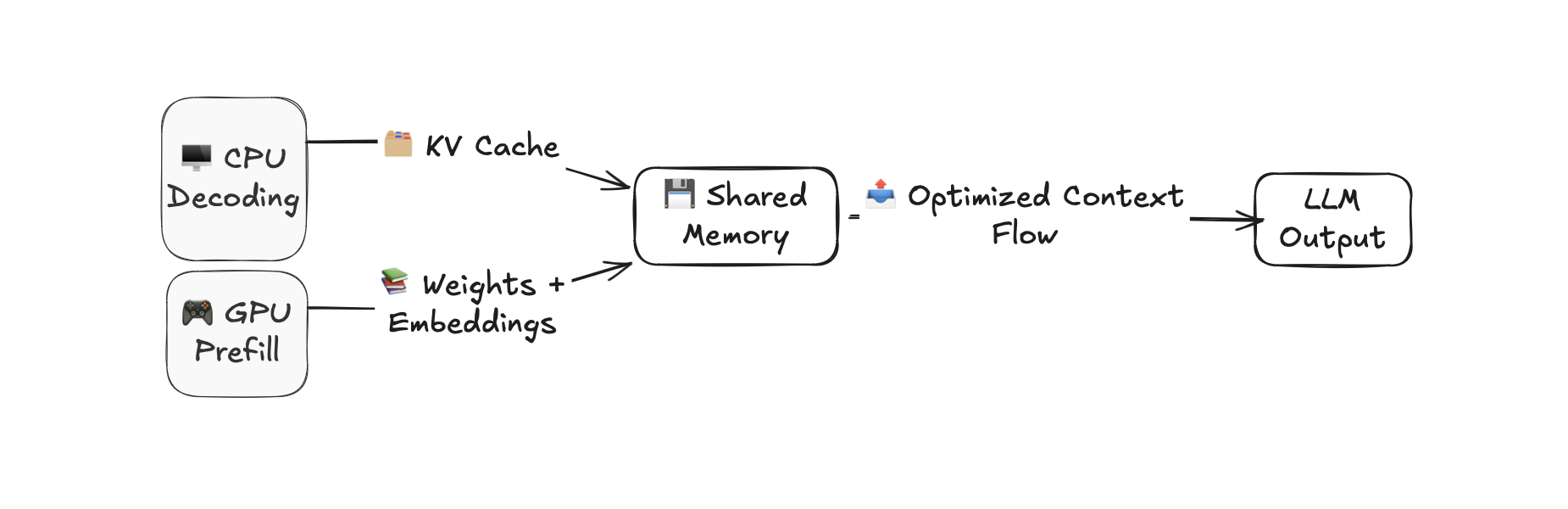
A hybrid execution system for ultra-long context LLM inference on consumer hardware. Built for LLaMA 3.2 1B, intelligently offloads decoding to CPU while maintaining GPU-accelerated prefill, doubling or quadrupling maximum context length.
A real-time, chemical-specific monitoring platform bringing awareness to chemical drift. Currently piloting with BlueWhite.
First place winner of MindState Ideation Competition.

Benchmarking and optimization framework for GROMACS molecular dynamics simulations using NVIDIA MPS. Achieved 30% throughput improvement for simulations ranging from 6k to 12M atoms.

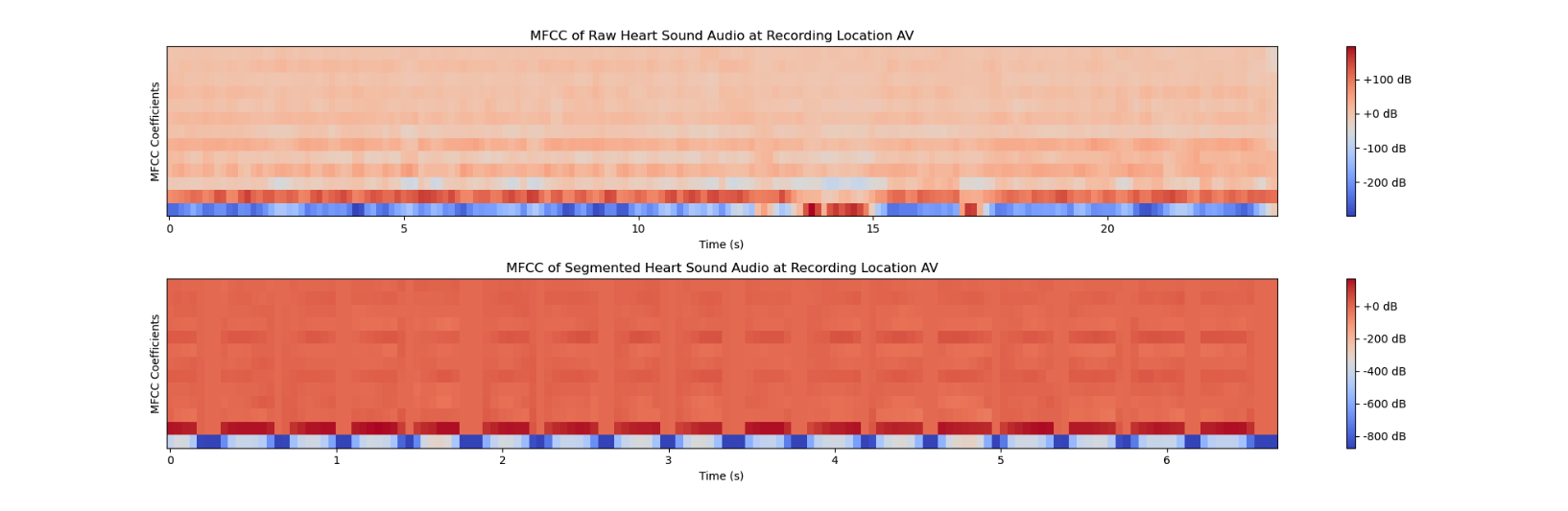
ML system for detecting heart murmurs in phonocardiogram recordings, optimized for resource-constrained healthcare settings. Achieved 86.67% recall with 96.03% precision using MFCC-based feature extraction.
TVM-based implementation of deep learning primitives (1D Conv, GEMM, 2D Depthwise) with hardware-specific optimizations. Achieved 220% speedup over baseline for CPU Conv through tiling, vectorization, and memory hierarchy optimizations.
Hardware-optimized speech recognition for resource-constrained devices. Achieved 75% parameter reduction and 18% runtime improvement while maintaining 85% accuracy through structured pruning and quantization-aware training.
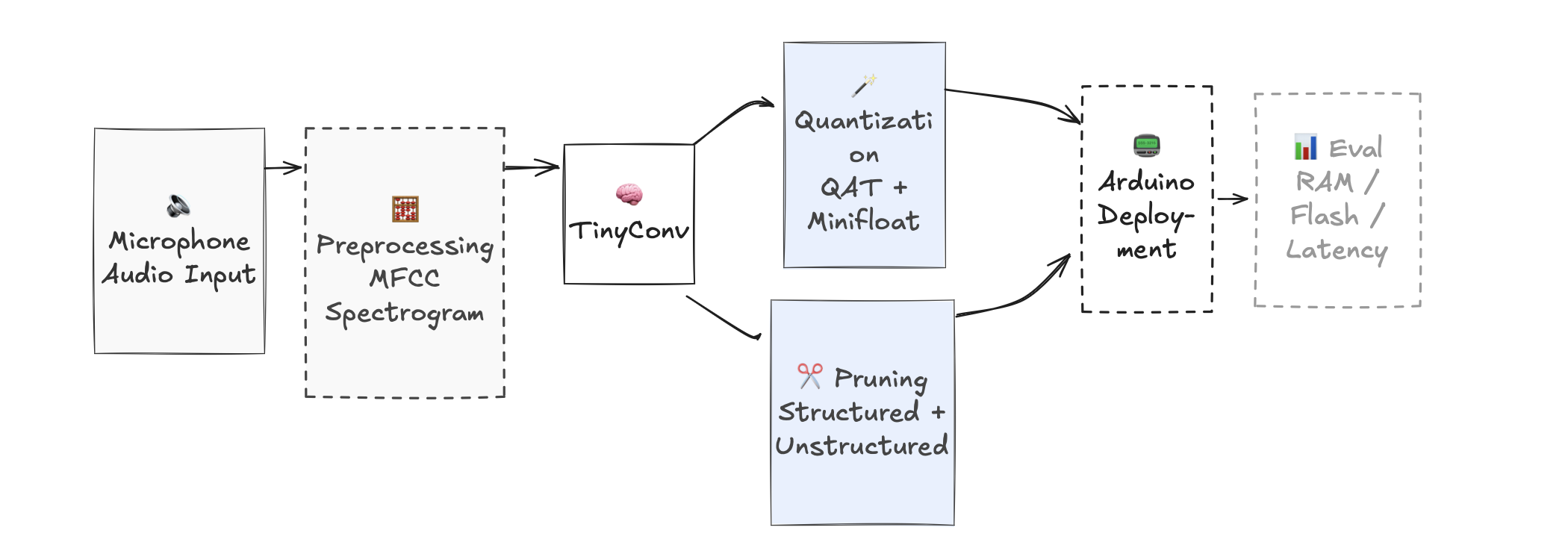
1st place at LlamaHack, a 100-person Cornell Tech hackathon open to all Ivy League students.

A DIY teaching library for ML engineers to learn about deep learning internals. Pure Python re-implementation of the Torch API designed to be simple, easy-to-read, tested, and incremental.
* Its like coffee with a y